За да намерите средната стойност в Excel (независимо дали е числова, текстова, процентна или друга стойност), има много функции. И всеки от тях има свои собствени характеристики и предимства. В крайна сметка в тази задача могат да се поставят определени условия.
Например, средните стойности на поредица от числа в Excel се изчисляват с помощта на статистически функции. Можете също така ръчно да въведете своя собствена формула. Нека разгледаме различни варианти.
Как да намерим средната аритметична стойност на числата?
За да намерите средното аритметично, трябва да съберете всички числа в набора и да разделите сбора на числото. Например оценките на ученик по информатика: 3, 4, 3, 5, 5. Какво се отнася за една четвърт: 4. Намерихме средното аритметично по формулата: \u003d (3 + 4 + 3 + 5 + 5) / 5.
Как да го направя бързо с помощта на функциите на Excel? Вземете например поредица от произволни числа в низ:

Или: направете клетката активна и просто въведете ръчно формулата: =СРЕДНО(A1:A8).
Сега нека видим какво още може да направи функцията AVERAGE.

Намерете средноаритметичната стойност на първите две и последните три числа. Формула: =СРЕДНО(A1:B1;F1:H1). Резултат:
Средно според условията
Условието за намиране на средноаритметичното може да бъде числен критерий или текстов критерий. Ще използваме функцията: =AVERAGEIF().
Намерете средната аритметична стойност на числа, които са по-големи или равни на 10.
Функция: =AVERAGEIF(A1:A8,">=10")
 Резултатът от използването на функцията AVERAGEIF при условието ">=10":
Резултатът от използването на функцията AVERAGEIF при условието ">=10": Третият аргумент - "Диапазон на осредняване" - е пропуснат. Първо, не е задължително. Второ, анализираният от програмата диапазон съдържа САМО числови стойности. В клетките, посочени в първия аргумент, търсенето ще се извърши според условието, посочено във втория аргумент.
внимание! Критерият за търсене може да бъде зададен в клетка. И във формулата да направя препратка към него.
Нека намерим средната стойност на числата по текстовия критерий. Например, средните продажби на продукта "маси".

Функцията ще изглежда така: =AVERAGEIF($A$2:$A$12;A7;$B$2:$B$12). Обхват - колона с имена на продукти. Критерият за търсене е връзка към клетка с думата "таблици" (можете да вмъкнете думата "таблици" вместо връзка A7). Диапазон на осредняване - тези клетки, от които ще бъдат взети данни за изчисляване на средната стойност.
В резултат на изчисляване на функцията получаваме следната стойност:
внимание! За текстов критерий (условие) трябва да се посочи диапазонът на осредняване.
Как да изчислим среднопретеглената цена в Excel?

Как да разберем среднопретеглената цена?
Формула: =SUMPRODUCT(C2:C12,B2:B12)/SUM(C2:C12).

Използвайки формулата SUMPRODUCT, намираме общия приход след продажбата на цялото количество стоки. А функцията SUM - сумира количеството стоки. Като разделим общия приход от продажбата на стоки на общия брой единици стоки, намерихме среднопретеглената цена. Този индикатор отчита "тежестта" на всяка цена. Делът му в общата маса на ценностите.
Стандартно отклонение: формула в Excel
Правете разлика между стандартното отклонение за генералната съвкупност и за извадката. В първия случай това е коренът на общата дисперсия. Във втория, от извадката дисперсия.
За изчисляване на този статистически показател се съставя дисперсионна формула. От него се взема коренът. Но в Excel има готова функция за намиране на стандартното отклонение.

Стандартното отклонение е свързано с мащаба на изходните данни. Това не е достатъчно за образно представяне на вариацията на анализирания диапазон. За да се получи относителното ниво на разсейване в данните, се изчислява коефициентът на вариация:
стандартно отклонение / средно аритметично
Формулата в Excel изглежда така:
STDEV (диапазон от стойности) / AVERAGE (диапазон от стойности).
Коефициентът на вариация се изчислява като процент. Затова задаваме процентния формат в клетката.
Средна работна заплата… Средна продължителностживот ... Почти всеки ден чуваме тези фрази, използвани за описание на множеството с едно число. Но колкото и да е странно, „средната стойност“ е доста коварна концепция, която често подвежда обикновен човек, който няма опит в математическата статистика.
Какъв е проблемът?
Под средна стойност най-често се разбира средноаритметичното, което силно варира под влияние на отделни факти или събития. И няма да получите реална представа как точно са разпределени ценностите, които учите.
Да вземем класически пример за средната заплата.
Една абстрактна компания има десет служители. Девет от тях получават заплата от около 50 000 рубли, а един - 1 500 000 рубли (по странно съвпадение той е и генерален директор на тази компания).
Средната стойност в този случай ще бъде 195 150 рубли, което, както виждате, е грешно.
Какви са начините за изчисляване на средната стойност?
Първият начин е да се изчисли вече споменатото средноаритметично, което е сумата от всички стойности, разделена на техния брой.

- x – средно аритметично;
- x n - специфична стойност;
- n - брой стойности.
- Работи добре с нормално разпределение на стойностите в извадката;
- Лесен за изчисляване;
- Интуитивен.
- Не дава реална представа за разпределението на стойностите;
- Нестабилно количество, което лесно се изхвърля (както в случая с главния изпълнителен директор).
Вторият начин е да се изчисли мода, което е най-често срещаната стойност.

- M 0 - режим;
- x0 е долната граница на интервала, който съдържа режима;
- n е стойността на интервала;
- f m - честота (колко пъти дадена стойност се среща в серия);
- f m-1 - честотата на интервала, предхождащ модалния;
- f m+1 е честотата на интервала, следващ модала.
- Чудесно за получаване на усещане за общественото мнение;
- Добър за нечислови данни (цветове на сезона, бестселъри, рейтинги);
- Лесно за разбиране.
- Модата може просто да не съществува (без повторения);
- Може да има няколко режима (мултимодално разпространение).
Третият начин е да се изчисли медиани, тоест стойността, която разделя подредената проба на две половини и се намира между тях. И ако няма такава стойност, тогава средноаритметичната стойност между границите на половините на извадката се приема като медиана.

- M e е медианата;
- x0 е долната граница на интервала, който съдържа медианата;
- h е стойността на интервала;
- f i - честота (колко пъти дадена стойност се среща в серия);
- S m-1 - сумата от честотите на интервалите, предхождащи медианата;
- f m е броят на стойностите в средния интервал (неговата честота).
- Предоставя най-реалистичната и представителна оценка;
- Устойчив на емисии.
- По-трудно е да се изчисли, тъй като пробата трябва да бъде поръчана преди изчислението.
Разгледахме основните методи за намиране на средната стойност, т.нар мерки на централната тенденция(всъщност има повече, но тези са най-популярните).
Сега нека се върнем към нашия пример и изчислим и трите варианта на средната стойност, като използваме специални функции на Excel:
- AVERAGE(число1;[число2];…) — функция за определяне на средно аритметично;
- FASHION.ONE(number1,[number2],...) - модна функция (по-старите версии на Excel използваха FASHION(number1,[number2],...));
- MEDIAN(число1;[число2];...) е функция за намиране на медианата.
И ето стойностите, които получихме:
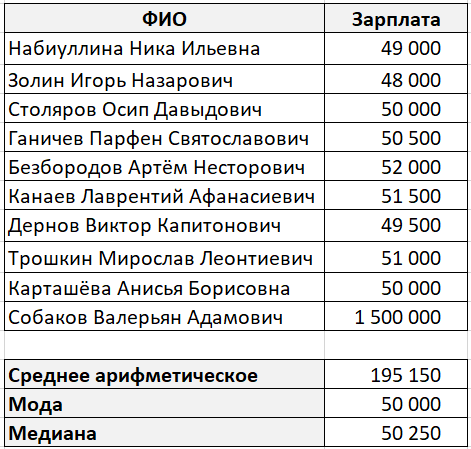
В този случай режимът и медианата характеризират много по-добре средната заплата в компанията.
Но какво да направите, когато в извадката няма 10 стойности, както в примера, а милиони? В Excel това не може да се изчисли, но в базата данни, където се съхраняват вашите данни, няма проблем.
Изчислете средноаритметичната стойност в SQL
Тук всичко е доста просто, тъй като SQL предоставя специална агрегатна функция AVG.
И за да го използвате, е достатъчно да напишете следната заявка:
Изчисляване на режима в SQL
SQL няма отделна функция за намиране на режима, но можете лесно и бързо да го напишете сами. За да направим това, трябва да разберем коя от заплатите се повтаря най-често и да изберем най-популярната.
Нека напишем запитване:
/* WITH TIES трябва да се добави към TOP(), ако наборът е мултимодален, което означава, че наборът има множество режими */ SELECT TOP(1) WITH TIES заплата КАТО „Режим на заплата“ ОТ служители ГРУПИРАНЕ ПО заплата ORDER BY COUNT(*) DESC
Изчислете медианата в SQL
Както при модата, SQL няма вградена функция за изчисляване на медианата, но има обща функция за изчисляване на процентили PERCENTILE_CONT.
Всичко изглежда така:
/* В този случай 0,5 процентилът ще бъде медианата */ ИЗБЕРЕТЕ TOP(1) PERCENTILE_CONT(0,5) В ГРУПАТА (ПОРЪД ПО заплата) OVER() КАТО "средна заплата" ОТ служители
По-добре е да прочетете повече за работата на функцията PERCENTILE_CONT в помощта на Microsoft и Google BigQuery.
Какъв начин да използвам все пак?
От горното следва, че медианата По най-добрия начинза изчисляване на средната стойност.
Но не винаги е така. Ако работите със средната стойност, пазете се от мултимодална дистрибуция:

Графиката показва бимодално разпределение с два пика. Такава ситуация може да възникне например при гласуване на избори.
В този случай средната аритметична стойност и медианата са стойности някъде по средата и те няма да кажат нищо за това, което наистина се случва и е по-добре веднага да разпознаете, че имате работа с бимодално разпределение, като докладвате два режима.
Още по-добре, разделете извадката на две групи и съберете статистически данни за всяка.
Заключение:
При избора на метод за намиране на средната стойност е необходимо да се вземе предвид наличието на извънредни стойности, както и нормалното разпределение на стойностите в извадката.
Окончателният избор на мярката на централната тенденция винаги е на анализатора.
Да приемем, че трябва да намерите средния брой дни за задачи, които трябва да бъдат изпълнени от различни служители. Освен това искате да изчислите средната температура за даден ден за период от 10 години. Изчисляването на средната стойност за група от числа може да се извърши по няколко начина.
Функцията AVERAGE изчислява средната стойност, която е центърът на набор от числа в статистическо разпределение. Има три най-често срещани начина за определяне на средната стойност:
ОзначаваТова е средната аритметична стойност, която се изчислява чрез добавяне на група числа и разделянето им на броя на тези числа. Например средната стойност за числата 2, 3, 3, 5, 7 и 10 е 5, което е резултат от разделянето на сбора им, който е 30, на техния брой, който е 6.
МедианаСредното число на група числа. Половината от числата съдържат стойности, по-големи от медианата, а половината от числата съдържат стойности, по-малки от медианата. Например медианата за числата 2, 3, 3, 5, 7 и 10 е 4.
МодаНай-често срещаното число в група числа. Например режимът за числата 2, 3, 3, 5, 7 и 10 ще бъде 3.
При симетрично разпределение на набор от числа и трите стойности на централната тенденция ще съвпадат. При отклонението на разпределението на група числа те могат да бъдат различни.
Изчислете средната стойност в съседни редове или колони
Следвайте стъпките по-долу.
Изчисляване на средната стойност извън непрекъснат ред или колона
За да изпълните тази задача, използвайте функцията СРЕДНО АРИТМЕТИЧНО. Копирайте таблицата по-долу на празен лист.
Изчисляване на среднопретеглената стойност
За да изпълните тази задача, използвайте функциите SUMPRODUCTи сума. Примерът на WWIS изчислява средните цени, платени за единица за три покупки, като всяка е за различен артикул на различна единица.
Копирайте таблицата по-долу на празен лист.
В повечето случаи данните са концентрирани около някаква централна точка. По този начин, за да се опише всеки набор от данни, е достатъчно да се посочи средната стойност. Разгледайте последователно три числени характеристики, които се използват за оценка на средната стойност на разпределението: средно аритметично, медиана и мода.
Средно аритметично
Средната аритметична стойност (често наричана просто средна) е най-често срещаната оценка на средната стойност на разпределение. Това е резултат от разделянето на сумата от всички наблюдавани числови стойности на техния брой. За проба на числата X 1, X 2, ..., Xн, средната стойност на извадката (обозначена със символа ) се равнява \u003d (X 1 + X 2 + ... + Xн) / н, или
къде е средната стойност на извадката, н- размер на извадката, хаз – i-ти елементпроби.
Изтеглете бележка в или формат, примери във формат
Помислете за изчисляване на средната аритметична стойност на петгодишната средна годишна възвръщаемост на 15 взаимни фонда с много високо нивориск (фиг. 1).

Ориз. 1. Средна годишна доходност на 15 взаимни фонда с много висок риск
Средната стойност на извадката се изчислява, както следва:

Това е добра възвръщаемост, особено в сравнение с 3-4% възвръщаемост, която вложителите в банка или кредитен съюз са получили за същия период от време. Ако сортирате стойностите на възвращаемостта, лесно можете да видите, че осем фонда имат доходност над, а седем - под средната. Средната аритметична стойност действа като точка на баланс, така че фондовете с ниски доходи балансират фондовете с високи доходи. Всички елементи на извадката участват в изчисляването на средната стойност. Нито един от другите оценители на средната стойност на разпределението няма това свойство.
Кога да се изчисли средноаритметичната стойност.Тъй като средноаритметичната стойност зависи от всички елементи на извадката, наличието на екстремни стойности значително влияе върху резултата. В такива ситуации средноаритметичната стойност може да изкриви значението на числовите данни. Следователно, когато се описва набор от данни, съдържащ екстремни стойности, е необходимо да се посочи медианата или средноаритметичното и медианата. Например, ако възвръщаемостта на фонда RS Emerging Growth бъде премахната от извадката, средната извадкова възвръщаемост на 14-те фонда намалява с почти 1% до 5,19%.
Медиана
Медианата е средната стойност на подреден масив от числа. Ако масивът не съдържа повтарящи се числа, тогава половината от неговите елементи ще бъдат по-малки от и половината повече от медианата. Ако извадката съдържа екстремни стойности, по-добре е да се използва медианата, а не средното аритметично, за да се оцени средната стойност. За да се изчисли медианата на извадка, тя първо трябва да бъде сортирана.
Тази формула е двусмислена. Резултатът му зависи от това дали числото е четно или нечетно. н:
- Ако извадката съдържа нечетен брой елементи, медианата е (n+1)/2-ти елемент.
- Ако извадката съдържа четен брой елементи, медианата се намира между двата средни елемента на извадката и е равна на средноаритметичната стойност, изчислена върху тези два елемента.
За да изчислим медианата за извадка от 15 взаимни фонда с много висок риск, първо трябва да сортираме необработените данни (Фигура 2). Тогава медианата ще бъде срещу номера на средния елемент на извадката; в нашия пример номер 8. Excel има специална функция =MEDIAN(), която работи и с неподредени масиви.

Ориз. 2. Медиана 15 средства
Така медианата е 6,5. Това означава, че половината от фондовете с много висок риск не надвишават 6,5, докато другата половина го правят. Имайте предвид, че медианата от 6,5 е малко по-голяма от медианата от 6,08.
Ако премахнем доходността на фонда RS Emerging Growth от извадката, тогава медианата на останалите 14 фонда ще намалее до 6,2%, тоест не толкова значително, колкото средноаритметичната (фиг. 3).

Ориз. 3. Медиана 14 средства
Мода
Терминът е въведен за първи път от Pearson през 1894 г. Fashion е числото, което се среща най-често в извадката (най-модерното). Модата описва добре, напр. типична реакцияшофьорите на пътен сигнал за спиране на движението. Класически пример за използване на модата е изборът на размера на произведената партида обувки или цвета на тапета. Ако едно разпределение има множество режими, тогава се казва, че е мултимодално или мултимодално (има два или повече „пика“). Мултимодалното разпределение предоставя важна информация за естеството на изследваната променлива. Например, в социологически проучвания, ако една променлива представлява предпочитание или отношение към нещо, тогава мултимодалността може да означава, че има няколко ясно различни мнения. Мултимодалността също е индикатор, че извадката не е хомогенна и че наблюденията могат да бъдат генерирани от две или повече „припокриващи се“ разпределения. За разлика от средноаритметичната стойност, отклоненията не влияят на режима. За непрекъснато разпределени случайни променливи, като средната годишна възвръщаемост на взаимните фондове, режимът понякога изобщо не съществува (или няма смисъл). Тъй като тези индикатори могат да приемат различни стойности, повтарящите се стойности са изключително редки.
Квартили
Квартилите са мерки, които най-често се използват за оценка на разпределението на данни, когато се описват свойствата на големи числени извадки. Докато медианата разделя подредения масив наполовина (50% от елементите на масива са по-малки от медианата и 50% са по-големи), квартилите разделят подредения набор от данни на четири части. Стойностите на Q 1, медианата и Q 3 са съответно 25-ти, 50-ти и 75-ти персентил. Първият квартил Q 1 е число, което разделя извадката на две части: 25% от елементите са по-малко от и 75% са повече от първия квартил.
Третият квартил Q 3 е число, което също разделя извадката на две части: 75% от елементите са по-малко от и 25% са повече от третия квартил.
За изчисляване на квартили във версии на Excel преди 2007 г. се използва функцията =QUARTILE(масив, част). Започвайки с Excel 2010, се прилагат две функции:
- =QUARTILE.ON(масив, част)
- =QUARTILE.EXC(масив, част)
Тези две функции дават малко по-различни стойности (Фигура 4). Например, когато се изчисляват квартилите на извадка, съдържаща данни за средната годишна доходност на 15 взаимни фонда с много висок риск, Q 1 = 1,8 или -0,7 съответно за QUARTILE.INC и QUARTILE.EXC. Между другото, използваната по-рано функция QUARTILE съответства на съвременната функция QUARTILE.ON. За да изчислите квартили в Excel с помощта на горните формули, масивът от данни може да бъде оставен неподреден.

Ориз. 4. Изчислете квартили в Excel
Нека отново подчертаем. Excel може да изчислява квартили за едномерни дискретна серия, съдържащ стойностите на случайна променлива. Изчисляването на квартилите за базирано на честота разпределение е дадено в раздела по-долу.
средно геометрично
За разлика от средното аритметично, средното геометрично измерва колко се е променила дадена променлива във времето. Средната геометрична е коренът нстепен от продукта нстойности (в Excel се използва функцията = CUGEOM):
Ж= (X 1 * X 2 * ... * X n) 1/n
Подобен параметър - средното геометрично на нормата на възвръщаемост - се определя по формулата:
G \u003d [(1 + R 1) * (1 + R 2) * ... * (1 + R n)] 1 / n - 1,
където R i- норма на възвръщаемост аз-ти период от време.
Да предположим например, че първоначалната инвестиция е $100 000. До края на първата година тя спада до $50 000, а до края на втората година се възстановява до първоначалните $100 000. Процентът на възвръщаемост на тази инвестиция за два годишен период е равен на 0, тъй като първоначалната и крайната сума на средствата са равни една на друга. Въпреки това средноаритметичната стойност на годишните норми на възвръщаемост е = (-0,5 + 1) / 2 = 0,25 или 25%, тъй като нормата на възвръщаемост през първата година R 1 = (50 000 - 100 000) / 100 000 = -0,5, и във втория R 2 = (100 000 - 50 000) / 50 000 = 1. В същото време средната геометрична стойност на нормата на възвръщаемост за две години е: G = [(1–0,5) * (1 + 1 )] 1 /2 – 1 = ½ – 1 = 1 – 1 = 0. По този начин средногеометричната стойност отразява по-точно промяната (по-точно липсата на промяна) в обема на инвестициите през двугодишния период, отколкото средноаритметичната.
Интересни факти.Първо, средното геометрично винаги ще бъде по-малко от средното аритметично на същите числа. С изключение на случая, когато всички взети числа са равни едно на друго. Второ, след като разгледахме свойствата на правоъгълен триъгълник, можем да разберем защо средната стойност се нарича геометрична. Височината на правоъгълен триъгълник, спусната до хипотенузата, е средната пропорционална стойност между проекциите на катетите върху хипотенузата, а всеки катет е средната пропорционална стойност между хипотенузата и неговата проекция върху хипотенузата (фиг. 5). Това дава геометричен начин за конструиране на средното геометрично на два (дължини) сегмента: трябва да изградите окръжност върху сумата от тези два сегмента като диаметър, след това височината, възстановена от точката на тяхната връзка до пресечната точка с кръг, ще даде необходимата стойност:

Ориз. 5. Геометричният характер на средното геометрично (фигура от Wikipedia)
Второто важно свойство на числовите данни е тяхното вариацияхарактеризиращ степента на дисперсия на данните. Две различни проби могат да се различават както по средни стойности, така и по вариации. Въпреки това, както е показано на фиг. 6 и 7, две проби могат да имат една и съща вариация, но различни средни стойности, или една и съща средна и напълно различна вариация. Данните, съответстващи на многоъгълник B на фиг. 7 се променят много по-малко от данните, от които е построен полигон А.

Ориз. 6. Две симетрични камбановидни разпределения с еднакво разпространение и различни средни стойности

Ориз. 7. Две симетрични камбановидни разпределения с еднакви средни стойности и различно разсейване
Има пет оценки за вариация на данните:
- педя,
- интерквартилен диапазон,
- дисперсия,
- стандартно отклонение,
- коефициентът на вариация.
обхват
Диапазонът е разликата между най-големия и най-малкия елемент на извадката:
Плъзнете = XМакс-XМин
Диапазонът на извадка, съдържаща средната годишна доходност на 15 взаимни фонда с много висок риск, може да бъде изчислен с помощта на подреден масив (вижте Фигура 4): диапазон = 18,5 - (-6,1) = 24,6. Това означава, че разликата между най-високата и най-ниската средна годишна доходност за фондовете с много висок риск е 24,6%.
Диапазонът измерва общото разпространение на данните. Въпреки че обхватът на извадката е много проста оценка на общото разпространение на данните, неговата слабост е, че не взема предвид точно как данните са разпределени между минималния и максималния елемент. Този ефект се вижда добре на фиг. 8, която илюстрира проби със същия диапазон. Скалата B показва, че ако извадката съдържа поне една екстремна стойност, диапазонът на извадката е много неточна оценка на разсейването на данните.

Ориз. 8. Сравнение на три проби с еднакъв диапазон; триъгълникът символизира опората на баланса, а местоположението му съответства на средната стойност на пробата
Интерквартилен диапазон
Интерквартилът или средният диапазон е разликата между третия и първия квартил на извадката:
Интерквартилен диапазон \u003d Q 3 - Q 1
Тази стойност позволява да се оцени разпространението на 50% от елементите и да не се отчита влиянието на екстремни елементи. Интерквартилният диапазон за извадка, съдържаща данни за средната годишна възвръщаемост на 15 много високорискови взаимни фонда, може да бъде изчислен с помощта на данните на фиг. 4 (например за функцията QUARTILE.EXC): Интерквартилен диапазон = 9,8 - (-0,7) = 10,5. Интервалът между 9,8 и -0,7 често се нарича средна половина.
Трябва да се отбележи, че стойностите на Q 1 и Q 3, а оттам и междуквартилният обхват, не зависят от наличието на извънредни стойности, тъй като тяхното изчисление не взема предвид стойност, която би била по-малка от Q 1 или по-голяма от Q 3 . Общите количествени характеристики, като медианата, първия и третия квартил и интерквартилния диапазон, които не се влияят от извънредни стойности, се наричат стабилни индикатори.
Докато обхватът и интерквартилният обхват предоставят съответно оценка на общото и средното разсейване на извадката, нито една от тези оценки не отчита точно как са разпределени данните. Дисперсия и стандартно отклонениесвободен от този недостатък. Тези индикатори ви позволяват да оцените степента на колебание на данните около средната стойност. Дисперсия на извадкатае приближение на средната аритметична стойност, изчислена от квадратните разлики между всеки елемент на извадката и средната извадка. За извадка от X 1 , X 2 , ... X n дисперсията на извадката (означена със символа S 2 се дава със следната формула:

Като цяло дисперсията на извадката е сумата от квадратите на разликите между елементите на извадката и средната извадка, разделена на стойност, равна на размера на извадката минус едно:

където - средноаритметично, н- размер на извадката, X i - аз-ти примерен елемент х. В Excel преди версия 2007 функцията =VAR() се използва за изчисляване на дисперсията на извадката, от версия 2010 се използва функцията =VAR.V().
Най-практичната и широко приета оценка на разсейването на данните е стандартно отклонение. Този показател се обозначава със символа S и е равен на корен квадратенот дисперсията на извадката:

В Excel преди версия 2007 функцията =STDEV() се използва за изчисляване на стандартното отклонение, от версия 2010 се използва функцията =STDEV.V(). За да се изчислят тези функции, масивът от данни може да бъде неподреден.
Нито дисперсията на извадката, нито стандартното отклонение на извадката могат да бъдат отрицателни. Единствената ситуация, при която показателите S 2 и S могат да бъдат нула, е ако всички елементи на извадката са равни. В този напълно невероятен случай диапазонът и интерквартилният диапазон също са нула.
Числовите данни по своята същност са непостоянни. Всяка променлива може да приема много различни стойности. Например различните взаимни фондове имат различни нива на възвръщаемост и загуба. Поради променливостта на числените данни е много важно да се изследват не само оценките на средната стойност, които са обобщаващи по природа, но и оценките на дисперсията, които характеризират разсейването на данните.
Дисперсията и стандартното отклонение ни позволяват да оценим разпространението на данните около средната стойност, с други думи, да определим колко елемента от извадката са по-малки от средната и колко са по-големи. Дисперсията има някои ценни математически свойства. Стойността му обаче е квадрат на единица мярка - квадратен процент, квадратен долар, квадратен инч и т.н. Следователно естествена оценка на дисперсията е стандартното отклонение, което се изразява в обичайните мерни единици - процент от дохода, долари или инчове.
Стандартното отклонение ви позволява да оцените степента на колебание на елементите на извадката около средната стойност. В почти всички ситуации по-голямата част от наблюдаваните стойности са в рамките на плюс или минус едно стандартно отклонение от средната стойност. Следователно, знаейки средното аритметично на елементите на извадката и стандартното отклонение на извадката, е възможно да се определи интервалът, към който принадлежи по-голямата част от данните.
Стандартното отклонение на възвръщаемостта на 15 взаимни фонда с много висок риск е 6,6 (Фигура 9). Това означава, че доходността на по-голямата част от фондовете се различава от средната стойност с не повече от 6,6% (т.е. тя варира в диапазона от - С= 6,2 – 6,6 = –0,4 до +S= 12,8). Всъщност този интервал съдържа петгодишна средна годишна възвръщаемост от 53,3% (8 от 15) средства.

Ориз. 9. Стандартно отклонение
Обърнете внимание, че в процеса на сумиране на квадратните разлики елементите, които са по-далеч от средната стойност, получават по-голяма тежест от елементите, които са по-близо. Това свойство е основната причина, поради която средната аритметична стойност най-често се използва за оценка на средната стойност на разпределение.
Коефициентът на вариация
За разлика от предишните оценки на разсейването, коефициентът на вариация е относителна оценка. Винаги се измерва като процент, а не в оригиналните единици данни. Коефициентът на вариация, означен със символите CV, измерва разсейването на данните около средната стойност. Коефициентът на вариация е равен на стандартното отклонение, разделено на средната аритметична стойност и умножено по 100%:

където С- стандартно отклонение на извадката, - извадкова средна стойност.
Коефициентът на вариация ви позволява да сравните две проби, чиито елементи са изразени в различни мерни единици. Например, мениджърът на услуга за доставка на поща възнамерява да обнови автопарка от камиони. Когато зареждате пакети, има два вида ограничения, които трябва да имате предвид: теглото (в паундове) и обемът (в кубични футове) на всеки пакет. Да приемем, че в проба от 200 торби средното тегло е 26,0 паунда, стандартното отклонение на теглото е 3,9 паунда, средният обем на опаковката е 8,8 кубически фута, а стандартното отклонение на обема е 2,2 кубични фута. Как да сравним разпределението на теглото и обема на пакетите?
Тъй като мерните единици за тегло и обем се различават една от друга, мениджърът трябва да сравни относителното разпространение на тези стойности. Коефициентът на вариация на теглото е CV W = 3,9 / 26,0 * 100% = 15%, а коефициентът на вариация на обема CV V = 2,2 / 8,8 * 100% = 25%. По този начин относителното разсейване на обемите на пакетите е много по-голямо от относителното разсейване на техните тегла.
Форма за разпространение
Третото важно свойство на извадката е формата на нейното разпределение. Това разпределение може да бъде симетрично или асиметрично. За да се опише формата на разпределение, е необходимо да се изчисли неговата средна стойност и медиана. Ако тези две мерки са еднакви, се казва, че променливата е симетрично разпределена. Ако средната стойност на дадена променлива е по-голяма от медианата, нейното разпределение има положителна асиметрия (фиг. 10). Ако медианата е по-голяма от средната, разпределението на променливата е отрицателно изкривено. Положителна асиметрия възниква, когато средната стойност се увеличи до необичайно високи стойности. Отрицателна асиметрия възниква, когато средната стойност намалее до необичайно малки стойности. Една променлива е симетрично разпределена, ако не приема никакви екстремни стойности в нито една посока, така че големи и малки стойности на променливата взаимно се компенсират.

Ориз. 10. Три вида разпределения
Данните, изобразени по скала А, имат отрицателна асиметрия. Тази фигура показва дълга опашка и ляво изкривяване, причинено от необичайно малки стойности. Тези изключително малки стойности изместват средната стойност наляво и тя става по-малка от медианата. Данните, показани в скала B, са разпределени симетрично. Лявата и дясната половина на разпределението са техните огледални изображения. Големите и малките стойности се балансират взаимно, а средната и медианата са равни. Данните, показани на скала B, имат положителна асиметрия. Тази фигура показва дълга опашка и изкривяване надясно, причинено от наличието на необичайно високи стойности. Тези твърде големи стойности изместват средната стойност надясно и тя става по-голяма от медианата.
В Excel може да се получи описателна статистика с помощта на добавката Пакет за анализ. Преминете през менюто Данни → Анализ на данни, в прозореца, който се отваря, изберете реда Описателна статистикаи щракнете Добре. В прозореца Описателна статистикане забравяйте да посочите интервал на въвеждане(фиг. 11). Ако искате да видите описателна статистика на същия лист като оригиналните данни, изберете бутона за избор изходен интервали посочете клетката, където искате да поставите горния ляв ъгъл на показаната статистика (в нашия пример $C$1). Ако искате да изпратите данни до нов листили в нова книгапросто изберете съответния бутон за избор. Поставете отметка в квадратчето до Крайна статистика. По желание можете също да изберете Ниво на трудност,k-тото най-малко иk-то по големина.
Ако е на депозит Даннив района на Анализне виждате иконата Анализ на данни, първо трябва да инсталирате добавката Пакет за анализ(виж, например,).

Ориз. 11. Описателна статистика на петгодишната средна годишна доходност на фондове с много високи нива на риск, изчислена с помощта на добавката Анализ на данни Excel програми
Excel изчислява редица статистически данни, обсъдени по-горе: средна стойност, медиана, режим, стандартно отклонение, дисперсия, диапазон ( интервал), минимум, максимум и размер на извадката ( проверка). Освен това Excel изчислява някои нови статистики за нас: стандартна грешка, ексцес и изкривяване. стандартна грешкае равно на стандартното отклонение, разделено на корен квадратен от размера на извадката. Асиметрияхарактеризира отклонението от симетрията на разпределението и е функция, която зависи от куба на разликите между елементите на извадката и средната стойност. Ексцесът е мярка за относителната концентрация на данни около средната стойност спрямо опашките на разпределението и зависи от разликите между извадката и средната стойност, повишена на четвърта степен.
Изчисляване на описателна статистика за генералната съвкупност
Средната стойност, разсейването и формата на разпределението, обсъдени по-горе, са характеристики, базирани на извадка. Въпреки това, ако наборът от данни съдържа числени измервания на цялата популация, тогава неговите параметри могат да бъдат изчислени. Тези параметри включват средна стойност, дисперсия и стандартно отклонение на популацията.
Очаквана стойносте равна на сумата от всички стойности на генералната съвкупност, разделена на обема на генералната съвкупност:

където µ - очаквана стойност, хаз- аз-та променлива наблюдение х, н- обемът на генералната съвкупност. В Excel за изчисляване на математическото очакване се използва същата функция като за средното аритметично: =AVERAGE().
Дисперсия на населениеторавна на сумата от квадратите на разликите между елементите на генералната съвкупност и мат. очакване, разделено на размера на населението:

където σ2е дисперсията на генералната съвкупност. Excel преди версия 2007 използва функцията =VAR() за изчисляване на дисперсията на популацията, започвайки с версия 2010 =VAR.G().
стандартно отклонение на населениетое равно на корен квадратен от дисперсията на популацията:

Excel преди версия 2007 използва =STDEV() за изчисляване на стандартното отклонение на популацията, като се започне от версия 2010 =STDEV.Y(). Обърнете внимание, че формулите за вариация на популацията и стандартно отклонение са различни от формулите за вариация на извадката и стандартно отклонение. При изчисляване на извадкова статистика S2и Сзнаменателят на дробта е n - 1, и при изчисляване на параметрите σ2и σ - обемът на генералната съвкупност н.
основно правило
В повечето ситуации голяма част от наблюденията са концентрирани около медианата, образувайки клъстер. В набори от данни с положителна асиметрия, този клъстер е разположен вляво (т.е. под) от математическото очакване, а в набори с отрицателна асиметрия този клъстер е разположен вдясно (т.е. отгоре) на математическото очакване. Симетричните данни имат една и съща средна стойност и медиана, а наблюденията се групират около средната стойност, образувайки разпределение във формата на камбана. Ако разпределението няма ясно изразено изкривяване и данните са концентрирани около определен център на тежестта, може да се използва правило за оценка на променливостта, което гласи: ако данните имат камбанообразно разпределение, тогава приблизително 68% от наблюденията са по-малко от едно стандартно отклонение от математическото очакване, Приблизително 95% от наблюденията са в рамките на две стандартни отклонения от очакваната стойност, а 99,7% от наблюденията са в рамките на три стандартни отклонения от очакваната стойност.
По този начин стандартното отклонение, което е оценка на средната флуктуация около математическото очакване, помага да се разбере как са разпределени наблюденията и да се идентифицират отклоненията. От основното правило следва, че за камбанообразните разпределения само една от двадесет стойности се различава от математическото очакване с повече от две стандартни отклонения. Следователно стойности извън интервала µ ± 2σ, могат да се считат за извънредни стойности. Освен това само три от 1000 наблюдения се различават от математическото очакване с повече от три стандартни отклонения. По този начин стойностите са извън интервала µ ± 3σпочти винаги са отклонения. За разпределения, които са силно изкривени или не са с форма на камбана, може да се приложи основното правило на Biename-Chebyshev.
Преди повече от сто години математиците Биенамай и Чебишев откриха независимо един от друг полезно свойствостандартно отклонение. Те откриха, че за всеки набор от данни, независимо от формата на разпределението, процентът наблюдения, които се намират на разстояние, което не надвишава кстандартни отклонения от математическото очакване, не по-малко (1 – 1/ 2)*100%.
Например ако к= 2, правилото на Biename-Chebyshev гласи, че най-малко (1 - (1/2) 2) x 100% = 75% от наблюденията трябва да се намират в интервала µ ± 2σ. Това правило е вярно за всеки кнадвишава едно. Правилото на Biename-Chebyshev е от много общ характер и е валидно за разпределения от всякакъв вид. Показва минималния брой наблюдения, разстоянието от които до математическото очакване не надвишава дадена стойност. Въпреки това, ако разпределението е с форма на камбана, основното правило оценява по-точно концентрацията на данни около средната стойност.
Изчисляване на описателна статистика за честотно базирано разпределение
Ако оригиналните данни не са налични, разпределението на честотата става единственият източник на информация. В такива ситуации можете да изчислите приблизителните стойности на количествените показатели на разпределението, като средно аритметично, стандартно отклонение, квартили.
Ако примерните данни са представени като честотно разпределение, може да се изчисли приблизителна стойност на средната аритметична стойност, като се приеме, че всички стойности във всеки клас са концентрирани в средната точка на класа:

където - извадкова средна стойност, н- брой наблюдения или размер на извадката, с- броя на класовете в честотното разпределение, mj- средна точка й-ти клас, fй- честота, съответстваща на й-ти клас.
За да се изчисли стандартното отклонение от честотното разпределение, също се приема, че всички стойности във всеки клас са концентрирани в средната точка на класа.

За да разберем как се определят квартилите на реда въз основа на честотите, нека разгледаме изчисляването на долния квартил въз основа на данните за 2013 г. за разпределението на руското население по среден паричен доход на глава от населението (фиг. 12).

Ориз. 12. Делът на населението на Русия с паричен доход на глава от населението средно на месец, рубли
За да изчислите първия квартил от серията интервални вариации, можете да използвате формулата:

където Q1 е стойността на първия квартил, xQ1 е долната граница на интервала, съдържащ първия квартил (интервалът се определя от натрупаната честота, като първата надвишава 25%); i е стойността на интервала; Σf е сумата от честотите на цялата извадка; вероятно винаги е равно на 100%; SQ1–1 е кумулативната честота на интервала, предхождащ интервала, съдържащ долния квартил; fQ1 е честотата на интервала, съдържащ долния квартил. Формулата за третия квартил се различава по това, че на всички места, вместо Q1, трябва да използвате Q3 и да замените ¾ вместо ¼.
В нашия пример (фиг. 12) долният квартил е в диапазона 7000,1 - 10 000, чиято кумулативна честота е 26,4%. Долната граница на този интервал е 7000 рубли, стойността на интервала е 3000 рубли, натрупаната честота на интервала, предхождащ интервала, съдържащ долния квартил, е 13,4%, честотата на интервала, съдържащ долния квартил, е 13,0%. Така: Q1 \u003d 7000 + 3000 * (¼ * 100 - 13,4) / 13 \u003d 9677 рубли.
Клопки, свързани с описателната статистика
В тази бележка разгледахме как да опишем набор от данни, използвайки различни статистики, които оценяват неговата средна стойност, разсейване и разпределение. Следващата стъпка е да анализирате и интерпретирате данните. Досега изучавахме обективните свойства на данните, а сега се обръщаме към тяхната субективна интерпретация. Две грешки чакат изследователя: неправилно избран предмет на анализ и неправилно тълкуване на резултатите.
Анализът на представянето на 15 взаимни фонда с много висок риск е доста безпристрастен. Той доведе до напълно обективни заключения: всички взаимни фондове имат различна доходност, спредът на доходността на фондовете варира от -6,1 до 18,5, а средната доходност е 6,08. Осигурена е обективност на анализа на данните правилният изборобщи количествени показатели на разпространение. Бяха разгледани няколко метода за оценка на средната стойност и разсейването на данните и бяха посочени техните предимства и недостатъци. Как да изберем правилната статистика, която предоставя обективен и безпристрастен анализ? Ако разпределението на данните е леко изкривено, трябва ли медианата да бъде избрана пред средната аритметична? Кой индикатор характеризира по-точно разпространението на данните: стандартно отклонение или диапазон? Трябва ли да се посочи положителната асиметрия на разпределението?
От друга страна, интерпретацията на данни е субективен процес. Различните хора стигат до различни заключения, тълкувайки едни и същи резултати. Всеки си има своя гледна точка. Някой смята общата средна годишна доходност на 15 фонда с много високо ниво на риск за добра и е доста доволен от получения доход. Други може да си помислят, че тези фондове имат твърде ниска възвръщаемост. Така субективизмът трябва да се компенсира от честност, неутралност и яснота на заключенията.
Етични въпроси
Анализът на данни е неразривно свързан с етичните въпроси. Човек трябва да бъде критичен към информацията, разпространявана от вестници, радио, телевизия и интернет. С времето ще се научите да бъдете скептични не само към резултатите, но и към целите, предмета и обективността на изследването. Известният британски политик Бенджамин Дизраели го каза най-добре: „Има три вида лъжи: лъжи, проклети лъжи и статистика.
Както е отбелязано в бележката, етични проблеми възникват при избора на резултатите, които трябва да бъдат представени в доклада. Трябва да се публикуват както положителните, така и отрицателните резултати. Освен това, когато се прави доклад или писмен доклад, резултатите трябва да бъдат представени честно, неутрално и обективно. Правете разлика между лоши и нечестни презентации. За целта е необходимо да се определи какви са били намеренията на говорещия. Понякога говорещият пропуска важна информация поради незнание, а понякога и умишлено (например, ако използва средната аритметична стойност, за да оцени средната стойност на ясно изкривени данни, за да получи желания резултат). Също така е нечестно да се премълчават резултати, които не отговарят на гледната точка на изследователя.
Използвани са материали от книгата Левин и др.Статистика за мениджъри. - М.: Уилямс, 2004. - стр. 178–209
Функцията QUARTILE е запазена за привеждане в съответствие с по-ранните версии на Excel
Средно аритметично - статистически показател, който показва средната стойност на даден масив от данни. Такъв индикатор се изчислява като дроб, чийто числител е сумата от всички стойности на масива, а знаменателят е техният брой. Средната аритметична стойност е важен коефициент, който се използва при изчисленията на домакинствата.
Значението на коеф
Средната аритметична стойност е елементарен показател за сравняване на данни и изчисляване на приемлива стойност. Например, кутия бира от определен производител се продава в различни магазини. Но в един магазин струва 67 рубли, в друг - 70 рубли, в трети - 65 рубли, а в последния - 62 рубли. Има доста голям диапазон от цени, така че купувачът ще се интересува от средната цена на кутия, така че при закупуване на продукт да може да сравни разходите си. Средно една кутия бира в града има цена:
Средна цена = (67 + 70 + 65 + 62) / 4 = 66 рубли.
Познавайки средната цена, лесно е да определите къде е изгодно да купувате стоки и къде ще трябва да надплатите.
Средната аритметична стойност се използва постоянно в статистическите изчисления в случаите, когато се анализира хомогенен набор от данни. В горния пример това е цената на кутия бира от същата марка. Не можем обаче да сравняваме цената на бирата от различни производители или цените на бирата и лимонадата, тъй като в този случай разпространението на стойностите ще бъде по-голямо, средната цена ще бъде замъглена и ненадеждна, а самият смисъл на изчисленията ще бъде изкривена до карикатурата "средна температура в болницата". За изчисляване на разнородни масиви от данни се използва средноаритметично претеглено, когато всяка стойност получава свой собствен коефициент на тежест.
Изчисляване на средно аритметично
Формулата за изчисление е изключително проста:
P = (a1 + a2 + … an) / n,
където an е стойността на количеството, n е общият брой стойности.
За какво може да се използва този индикатор? Първата и очевидна употреба е в статистиката. Почти всяко статистическо изследване използва средно аритметично. Може да бъде средна възрастбрак в Русия, средната оценка по предмет за ученик или средните разходи за хранителни стоки на ден. Както бе споменато по-горе, без да се вземат предвид теглата, изчисляването на средните може да даде странни или абсурдни стойности.
Например президентът Руска федерациянаправи изявление, че според статистиката средната заплата на руснак е 27 000 рубли. За повечето хора в Русия това ниво на заплата изглеждаше абсурдно. Не е изненадващо, ако изчислението вземе предвид доходите на олигарси, ръководители на промишлени предприятия, големи банкери, от една страна, и заплатите на учители, чистачи и продавачи, от друга. Дори средните заплати в една специалност, например счетоводител, ще имат сериозни разлики в Москва, Кострома и Екатеринбург.
Как да изчислим средни стойности за разнородни данни
В ситуации на заплати е важно да се вземе предвид тежестта на всяка стойност. Това означава, че заплатите на олигарсите и банкерите ще получат тежест например 0,00001, а заплатите на продавачите ще бъдат 0,12. Това са цифри от тавана, но те грубо илюстрират преобладаването на олигарсите и продажниците в руското общество.
По този начин, за да се изчисли средната стойност на средните стойности или средната стойност в разнороден масив от данни, е необходимо да се използва среднопретеглената аритметична стойност. В противен случай ще получите средна заплата в Русия на ниво от 27 000 рубли. Ако искате да знаете средната си оценка по математика или средния брой отбелязани голове от избран хокеист, тогава средноаритметичният калкулатор ще ви подхожда.
Нашата програма е прост и удобен калкулатор за изчисляване на средно аритметично. Трябва само да въведете стойности на параметрите, за да извършите изчисления.
Нека да разгледаме няколко примера
Изчисляване на средна оценка
Много учители използват средноаритметичния метод за определяне на годишна оценка по даден предмет. Да си представим, че едно дете получава следните четвърти оценки по математика: 3, 3, 5, 4. Каква годишна оценка ще му постави учителят? Нека използваме калкулатор и изчислим средноаритметичното. Първо изберете съответния брой полета и въведете стойностите на оценката в появилите се клетки:
(3 + 3 + 5 + 4) / 4 = 3,75
Учителят ще закръгли стойността в полза на ученика, а ученикът ще получи солидна четворка за годината.
Изчисляване на изядените сладкиши
Нека да илюстрираме някакъв абсурд на средното аритметично. Представете си, че Маша и Вова са имали 10 сладкиши. Маша изяде 8 бонбона, а Вова само 2. Колко бонбона изяде средно всяко дете? С помощта на калкулатор е лесно да се изчисли, че средно децата са изяли по 5 сладки, което е напълно невярно и разумно. Този пример показва, че средната аритметична стойност е важна за смислени набори от данни.
Заключение
Изчисляването на средноаритметичната стойност се използва широко в много научни области. Този показател е популярен не само в статистическите изчисления, но и във физиката, механиката, икономиката, медицината или финансите. Използвайте нашите калкулатори като помощник за решаване на средноаритметични задачи.