Na nájdenie priemernej hodnoty v Exceli (bez ohľadu na to, či ide o číselnú, textovú, percentuálnu alebo inú hodnotu) existuje veľa funkcií. A každý z nich má svoje vlastné vlastnosti a výhody. V tejto úlohe môžu byť stanovené určité podmienky.
Napríklad priemerné hodnoty série čísel v Exceli sa vypočítavajú pomocou štatistických funkcií. Môžete tiež ručne zadať svoj vlastný vzorec. Zvážme rôzne možnosti.
Ako nájsť aritmetický priemer čísel?
Ak chcete nájsť aritmetický priemer, musíte sčítať všetky čísla v množine a rozdeliť súčet množstvom. Napríklad známky študenta z informatiky: 3, 4, 3, 5, 5. Čo je zahrnuté v štvrťroku: 4. Aritmetický priemer sme zistili pomocou vzorca: =(3+4+3+5+5) /5.
Ako to rýchlo urobiť pomocou funkcií Excelu? Vezmime si napríklad sériu náhodných čísel v reťazci:

Alebo: vytvorte aktívnu bunku a jednoducho zadajte vzorec ručne: =AVERAGE(A1:A8).
Teraz sa pozrime, čo ešte funkcia AVERAGE dokáže.

Nájdite aritmetický priemer prvých dvoch a posledných troch čísel. Vzorec: =AVERAGE(A1:B1,F1:H1). výsledok:
Priemerný stav
Podmienkou na zistenie aritmetického priemeru môže byť číselné kritérium alebo textové kritérium. Použijeme funkciu: =AVERAGEIF().
Nájdite aritmetický priemer čísel, ktoré sú väčšie alebo rovné 10.
Funkcia: =AVERAGEIF(A1:A8,">=10")
 Výsledok použitia funkcie AVERAGEIF za podmienky ">=10":
Výsledok použitia funkcie AVERAGEIF za podmienky ">=10": Tretí argument – „Priemerný rozsah“ – je vynechaný. V prvom rade sa to nevyžaduje. Po druhé, rozsah analyzovaný programom obsahuje LEN číselné hodnoty. Bunky špecifikované v prvom argumente budú vyhľadávané podľa podmienky špecifikovanej v druhom argumente.
Pozor! Kritériá vyhľadávania je možné zadať v bunke. A urobte naň odkaz vo vzorci.
Nájdite priemernú hodnotu čísel pomocou textového kritéria. Napríklad priemerný predaj produktu „tabuľky“.

Funkcia bude vyzerať takto: =AVERAGEIF($A$2:$A$12,A7,$B$2:$B$12). Rozsah – stĺpec s názvami produktov. Kritériom vyhľadávania je odkaz na bunku so slovom „tabuľky“ (namiesto odkazu A7 môžete vložiť slovo „tabuľky“). Rozsah priemerovania – bunky, z ktorých sa budú brať údaje na výpočet priemernej hodnoty.
Ako výsledok výpočtu funkcie dostaneme nasledujúcu hodnotu:
Pozor! Pre textové kritérium (podmienku) musí byť špecifikovaný rozsah priemerovania.
Ako vypočítať váženú priemernú cenu v Exceli?

Ako sme zistili váženú priemernú cenu?
Vzorec: =SUMPRODUCT(C2:C12,B2:B12)/SUM(C2:C12).

Pomocou vzorca SUMPRODUCT zistíme celkovú tržbu po predaji celého množstva tovaru. A funkcia SUM sumarizuje množstvo tovaru. Vydelením celkových príjmov z predaja tovaru celkovým počtom jednotiek tovaru sme zistili váženú priemernú cenu. Tento ukazovateľ zohľadňuje „váhu“ každej ceny. Jeho podiel na celkovej mase hodnôt.
Smerodajná odchýlka: vzorec v Exceli
Existujú štandardné odchýlky pre všeobecnú populáciu a pre vzorku. V prvom prípade ide o koreň všeobecného rozptylu. V druhom z rozptylu vzorky.
Na výpočet tohto štatistického ukazovateľa sa zostaví vzorec rozptylu. Z nej sa extrahuje koreň. Ale v Exceli je pripravená funkcia na nájdenie smerodajnej odchýlky.

Smerodajná odchýlka je viazaná na rozsah zdrojových údajov. Na obrazové znázornenie variácie analyzovaného rozsahu to nestačí. Na získanie relatívnej úrovne rozptylu údajov sa vypočíta variačný koeficient:
smerodajná odchýlka / aritmetický priemer
Vzorec v Exceli vyzerá takto:
STDEV (rozsah hodnôt) / AVERAGE (rozsah hodnôt).
Variačný koeficient sa vypočíta v percentách. Preto v bunke nastavíme percentuálny formát.
Priemerná mzda… Priemerná dĺžka trvaniaživot... Takmer každý deň počujeme tieto frázy používané na označenie množiny s jedným jediným číslom. Ale napodiv, „priemerná hodnota“ je dosť zákerný pojem, ktorý často zavádza priemerného človeka, neskúseného v matematických štatistikách.
Aký je problém?
Priemernou hodnotou sa najčastejšie rozumie aritmetický priemer, ktorý sa pod vplyvom jednotlivých faktov alebo udalostí značne mení. A nezískate skutočnú predstavu o tom, ako presne sú distribuované hodnoty, ktoré študujete.
Pozrime sa na klasický príklad priemerného platu.
Nejaká abstraktná firma má desať zamestnancov. Deväť z nich dostáva plat okolo 50 000 rubľov a jeden dostáva plat 1 500 000 rubľov (zvláštnou zhodou okolností je zároveň generálnym riaditeľom tejto spoločnosti).
Priemerná hodnota v v tomto prípade bude to 195 150 rubľov, čo je podľa vás nesprávne.
Aké metódy výpočtu priemeru existujú?
Prvým spôsobom je výpočet už spomínaného aritmetický priemer, čo je súčet všetkých hodnôt vydelený ich počtom.

- x – aritmetický priemer;
- x n – špecifický význam;
- n – počet hodnôt.
- Funguje dobre s normálnym rozložením hodnôt vo vzorke;
- Ľahko vypočítať;
- Intuitívne jasné.
- Nedáva skutočnú predstavu o rozdelení hodnôt;
- Nestála veličina, ktorá ľahko podlieha odľahlým hodnotám (ako v prípade generálneho riaditeľa).
Druhým spôsobom je výpočet móda, teda najčastejšie sa vyskytujúca hodnota.

- M 0 – režim;
- x 0 – spodná hranica intervalu, ktorý obsahuje režim;
- n – intervalová hodnota;
- f m – frekvencia (koľkokrát sa určitá hodnota vyskytuje v rade);
- f m-1 – frekvencia intervalu predchádzajúceho modálnemu;
- f m+1 – frekvencia intervalu nasledujúceho po modálnom.
- Skvelé na získanie zmyslu pre verejnú mienku;
- Dobré pre nečíselné údaje (farby sezóny, najpredávanejšie, hodnotenia);
- Ľahko pochopiteľné.
- Móda možno jednoducho neexistuje (žiadne opakovania);
- Môže existovať niekoľko režimov (multimodálna distribúcia).
Tretím spôsobom je výpočet mediány, teda hodnotu, ktorá rozdeľuje usporiadanú vzorku na dve polovice a leží medzi nimi. A ak takáto hodnota neexistuje, potom sa ako medián berie aritmetický priemer medzi hranicami polovíc vzorky.

- M e – medián;
- x 0 – dolná hranica intervalu, ktorý obsahuje medián;
- h – intervalová hodnota;
- f i – frekvencia (koľkokrát sa určitá hodnota vyskytuje v rade);
- S m-1 – súčet frekvencií intervalov predchádzajúcich mediánu;
- f m – počet hodnôt v strednom intervale (jeho frekvencia).
- Poskytuje najrealistickejší a najreprezentatívnejší odhad;
- Odolný voči emisiám.
- Náročnejšie na výpočet, pretože vzorka musí byť objednaná pred výpočtom.
Pozreli sme sa na hlavné metódy zisťovania priemernej hodnoty, tzv opatrenia centrálnej tendencie(v skutočnosti je ich viac, ale tieto sú najobľúbenejšie).
Teraz sa vráťme k nášmu príkladu a vypočítajme všetky tri možnosti pre priemer pomocou špeciálnych funkcií programu Excel:
- AVERAGE(číslo1;[číslo2];…) – funkcia na určenie aritmetického priemeru;
- MODE.ONE(číslo1;[číslo2];...) - funkcia režimu (v starších verziách Excelu bola použitá MODE(číslo1;[číslo2];...));
- MEDIÁN(číslo1;[číslo2];...) – funkcia na nájdenie mediánu.
A tu sú hodnoty, ktoré sme získali:
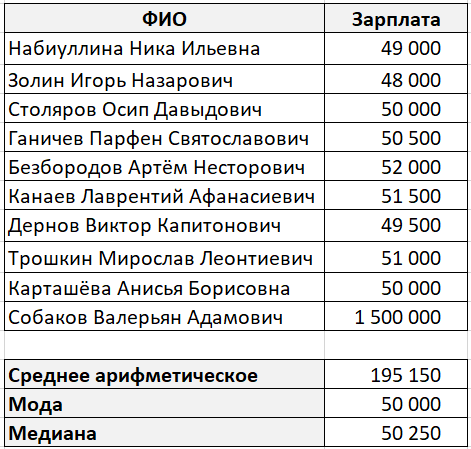
V tomto prípade režim a medián oveľa lepšie charakterizujú priemernú mzdu vo firme.
Čo však robiť, keď vzorka neobsahuje 10 hodnôt ako v príklade, ale milióny? V Exceli sa to nedá vypočítať, ale v databáze, kde máte uložené dáta, žiadny problém.
Výpočet aritmetického priemeru v SQL
Všetko je tu celkom jednoduché, pretože SQL poskytuje špeciálnu súhrnnú funkciu AVG.
A ak ho chcete použiť, stačí napísať nasledujúci dotaz:
Výpočet módy v SQL
V SQL neexistuje žiadna samostatná funkcia na nájdenie režimu, ale môžete si ju rýchlo a jednoducho napísať sami. K tomu musíme zistiť, ktorý plat sa najčastejšie opakuje a vybrať si ten najobľúbenejší.
Napíšeme žiadosť:
/* S VÄZBAMI je potrebné pridať do TOP() ak je zostava multimodálna, to znamená, že zostava má niekoľko režimov */ VYBERTE NAJLEPŠIE(1) S VÄZBAMI plat AKO "Mzdový režim" OD zamestnancov ZOSKUPOVAŤ PODĽA platu PORADIE PODĽA POČTU(* ) DESC
Výpočet mediánu v SQL
Rovnako ako režim, SQL nemá vstavanú funkciu na výpočet mediánu, ale má všeobecnú funkciu na výpočet percentilov, PERCENTILE_CONT .
Všetko to vyzerá takto:
/* V tomto prípade je percentil 0,5 a bude to medián */ VYBERTE TOP(1) PERCENTILE_CONT(0,5) V RÁMCI SKUPINY (ORDER PODĽA platu) NAD() AKO "MEDIANSKÁ mzda" OD zamestnancov
O fungovaní funkcie PERCENTILE_CONT je lepšie si prečítať viac v pomocníkovi Microsoft a Google BigQuery.
Akú metódu mám použiť?
Z uvedeného vyplýva, že medián Najlepšia cesta na výpočet priemeru.
Ale nie vždy to tak je. Ak pracujete s priemerom, dajte si pozor na multimodálnu distribúciu:

Graf ukazuje bimodálnu distribúciu s dvoma vrcholmi. Táto situácia môže nastať napríklad pri hlasovaní vo voľbách.
Aritmetický priemer a medián sú v tomto prípade hodnoty, ktoré sú niekde v strede a nepovedia nič o tom, čo sa vlastne deje a je lepšie okamžite rozpoznať, že máte do činenia s bimodálnym rozdelením nahlásením dvoch režimov.
Ešte lepšie je rozdeliť vzorku do dvoch skupín a pre každú zozbierať štatistické údaje.
Záver:
Pri výbere metódy na zistenie priemeru musíte vziať do úvahy prítomnosť odľahlých hodnôt, ako aj normálnosť rozloženia hodnôt vo vzorke.
Konečný výber miery centrálnej tendencie je vždy na analytikovi.
Povedzme, že potrebujete zistiť priemerný počet dní pre rôznych zamestnancov na dokončenie úloh. Okrem toho chcete vypočítať priemernú teplotu pre konkrétny deň počas 10-ročného časového obdobia. Výpočet priemeru skupiny čísel možno vykonať niekoľkými spôsobmi.
Funkcia AVERAGE vypočíta strednú hodnotu, ktorá je stredom množiny čísel v štatistickom rozdelení. Existujú tri najbežnejšie spôsoby, ako určiť priemer:
Priemerná hodnota Toto je aritmetický priemer, ktorý sa vypočíta sčítaním skupiny čísel a ich delením počtom týchto čísel. Napríklad priemer čísel 2, 3, 3, 5, 7 a 10 je 5, čo je výsledok vydelenia ich súčtu 30 ich súčtom 6.
Medián Stredné číslo skupiny čísel. Polovica čísel obsahuje hodnoty väčšie ako medián a polovica čísel obsahuje hodnoty menšie ako medián. Napríklad medián pre čísla 2, 3, 3, 5, 7 a 10 by bol 4.
Móda Najbežnejšie číslo v skupine čísel. Napríklad režim pre čísla 2, 3, 3, 5, 7 a 10 by bol 3.
Pri symetrickom rozložení množiny čísel sa budú všetky tri hodnoty centrálnej tendencie zhodovať. V odchýlenom rozložení skupiny čísel môžu byť rôzne.
Vypočítajte priemer susedných riadkov alebo stĺpcov
Postupujte podľa nižšie uvedených krokov.
Výpočet priemeru za súvislým riadkom alebo stĺpcom
Ak chcete vykonať túto úlohu, použite funkciu PRIEMERNÝ. Skopírujte tabuľku nižšie na prázdny list papiera.
Výpočet váženého priemeru
Ak chcete vykonať túto úlohu, použite funkcie SUMPRODUCT A Sum. Príklad VSIS vypočítava priemerné ceny zaplatené za jednotku v troch nákupoch, každý za inú položku na inej jednotke.
Skopírujte tabuľku nižšie na prázdny list papiera.
Vo väčšine prípadov sú údaje sústredené okolo nejakého centrálneho bodu. Na opísanie akéhokoľvek súboru údajov teda stačí uviesť priemernú hodnotu. Uvažujme postupne tri číselné charakteristiky, ktoré sa používajú na odhad priemernej hodnoty rozdelenia: aritmetický priemer, medián a modus.
Priemerná
Aritmetický priemer (často nazývaný jednoducho priemer) je najbežnejším odhadom priemeru rozdelenia. Je to výsledok vydelenia súčtu všetkých pozorovaných číselných hodnôt ich počtom. Pre vzorku pozostávajúcu z čísel X 1, X 2, ..., Xn, vzorový priemer (označený ) sa rovná = (X1 + X2 + … + Xn) / n, alebo
kde je priemer vzorky, n- veľkosť vzorky, Xi – i-tý prvok vzorky.
Stiahnite si poznámku vo formáte alebo formáte, príklady vo formáte
Zvážte výpočet aritmetického priemeru päťročných priemerných ročných výnosov 15 podielových fondov s veľmi vysoký stupeň riziko (obr. 1).

Ryža. 1. Priemerné ročné výnosy 15 veľmi rizikových podielových fondov
Priemer vzorky sa vypočíta takto:

Ide o dobrý výnos, najmä v porovnaní s výnosom 3 – 4 %, ktorý vkladatelia bánk alebo družstevných bánk dostali za rovnaké časové obdobie. Ak zoradíme výnosy, ľahko zistíme, že osem fondov má výnosy nad priemerom a sedem pod priemerom. Aritmetický priemer funguje ako bod rovnováhy, takže fondy s nízkymi výnosmi vyvažujú prostriedky s vysokými výnosmi. Všetky prvky vzorky sa podieľajú na výpočte priemeru. Žiadny z ostatných odhadov priemeru rozdelenia nemá túto vlastnosť.
Kedy by ste mali vypočítať aritmetický priemer? Keďže aritmetický priemer závisí od všetkých prvkov vo vzorke, prítomnosť extrémnych hodnôt významne ovplyvňuje výsledok. V takýchto situáciách môže aritmetický priemer skresliť význam číselných údajov. Preto pri popise súboru údajov obsahujúcich extrémne hodnoty je potrebné uviesť medián alebo aritmetický priemer a medián. Napríklad, ak zo vzorky odstránime výnosy fondu RS Emerging Growth, priemerná vzorka výnosov 14 fondov sa zníži o takmer 1 % na 5,19 %.
Medián
Medián predstavuje strednú hodnotu usporiadaného poľa čísel. Ak pole neobsahuje opakujúce sa čísla, polovica jeho prvkov bude menšia a polovica väčšia ako medián. Ak vzorka obsahuje extrémne hodnoty, je lepšie použiť na odhad priemeru skôr medián ako aritmetický priemer. Na výpočet mediánu vzorky je potrebné ju najskôr objednať.
Tento vzorec je nejednoznačný. Jeho výsledok závisí od toho, či je číslo párne alebo nepárne n:
- Ak vzorka obsahuje nepárny počet prvkov, medián je (n+1)/2- prvok.
- Ak vzorka obsahuje párny počet prvkov, medián leží medzi dvoma strednými prvkami vzorky a rovná sa aritmetickému priemeru vypočítanému pre tieto dva prvky.
Na výpočet mediánu vzorky obsahujúcej výnosy 15 veľmi rizikových podielových fondov musíte najskôr zoradiť nespracované údaje (obrázok 2). Potom bude medián oproti číslu stredného prvku vzorky; v našom príklade č.8. Excel má špeciálnu funkciu =MEDIAN(), ktorá pracuje aj s neusporiadanými poľami.

Ryža. 2. Medián 15 fondov
Medián je teda 6,5. To znamená, že výnos jednej polovice veľmi rizikových fondov nepresahuje 6,5 a výnos druhej polovice ju prevyšuje. Všimnite si, že medián 6,5 nie je oveľa väčší ako priemer 6,08.
Ak zo vzorky odstránime výnos fondu RS Emerging Growth, potom sa medián zvyšných 14 fondov zníži na 6,2 %, teda nie tak výrazne ako aritmetický priemer (obrázok 3).

Ryža. 3. Medián 14 fondov
Móda
Termín prvýkrát vytvoril Pearson v roku 1894. Móda je číslo, ktoré sa vo vzorke vyskytuje najčastejšie (najmódnejšie). Móda dobre opisuje napr. typická reakcia vodiči na semafore zastaviť premávku. Klasickým príkladom využitia módy je výber veľkosti topánok či farby tapety. Ak má distribúcia niekoľko režimov, potom sa hovorí, že je multimodálna alebo multimodálna (má dva alebo viac „vrcholov“). Multimodalita distribúcie poskytuje dôležité informácie o povahe skúmanej premennej. Napríklad v sociologických prieskumoch, ak premenná predstavuje preferenciu alebo postoj k niečomu, potom multimodalita môže znamenať, že existuje niekoľko výrazne odlišných názorov. Multimodalita tiež slúži ako indikátor toho, že vzorka nie je homogénna a pozorovania môžu byť generované dvoma alebo viacerými „prekrývajúcimi sa“ distribúciami. Na rozdiel od aritmetického priemeru odľahlé hodnoty neovplyvňujú režim. Pre priebežne distribuované náhodné premenné, ako je priemerný ročný výnos podielových fondov, režim niekedy vôbec neexistuje (alebo nemá zmysel). Keďže tieto indikátory môžu nadobúdať veľmi odlišné hodnoty, opakujúce sa hodnoty sú extrémne zriedkavé.
Kvartily
Kvartily sú metriky, ktoré sa najčastejšie používajú na vyhodnotenie distribúcie údajov pri popise vlastností veľkých numerických vzoriek. Zatiaľ čo medián rozdeľuje usporiadané pole na polovicu (50 % prvkov poľa je menších ako medián a 50 % je väčších), kvartily rozdeľujú usporiadaný súbor údajov na štyri časti. Hodnoty Q 1, mediánu a Q 3 sú 25., 50. a 75. percentil. Prvý kvartil Q 1 je číslo, ktoré rozdeľuje vzorku na dve časti: 25 % prvkov je menších ako prvý kvartil a 75 % je väčších ako prvý kvartil.
Tretí kvartil Q 3 je číslo, ktoré tiež rozdeľuje vzorku na dve časti: 75 % prvkov je menších a 25 % je väčších ako tretí kvartil.
Na výpočet kvartilov vo verziách Excelu pred rokom 2007 použite funkciu =QUARTILE(pole,časť). Od Excelu 2010 sa používajú dve funkcie:
- =QUARTILE.ON(pole,časť)
- =QUARTILE.EXC(pole,časť)
Tieto dve funkcie poskytujú mierne odlišné hodnoty (obrázok 4). Napríklad pri výpočte kvartilov vzorky obsahujúcej priemerné ročné výnosy 15 veľmi rizikových podielových fondov, Q 1 = 1,8 alebo –0,7 pre QUARTILE.IN a QUARTILE.EX, v tomto poradí. Mimochodom, predtým používaná funkcia QUARTILE zodpovedá modernej funkcii QUARTILE.ON. Na výpočet kvartilov v Exceli pomocou vyššie uvedených vzorcov nie je potrebné usporiadať dátové pole.

Ryža. 4. Výpočet kvartilov v Exceli
Ešte raz zdôraznime. Excel dokáže vypočítať kvartily pre jednu premennú diskrétne série, ktorý obsahuje hodnoty náhodnej premennej. Výpočet kvartilov pre frekvenčné rozdelenie je uvedený nižšie v časti.
Geometrický priemer
Na rozdiel od aritmetického priemeru vám geometrický priemer umožňuje odhadnúť mieru zmeny premennej v čase. Geometrický priemer je koreň n stupeň z práce n veličiny (v Exceli sa používa funkcia =SRGEOM):
G= (X 1 * X 2 * ... * X n) 1/n
Podobný parameter - geometrická stredná hodnota miery zisku - je určený vzorcom:
G = [(1 + R 1) * (1 + R 2) * … * (1 + R n)] 1/n – 1,
Kde RI– miera zisku za ičasové obdobie.
Predpokladajme napríklad, že počiatočná investícia je 100 000 USD. Do konca prvého roka klesne na 50 000 USD a do konca druhého roka sa vráti na počiatočnú úroveň 100 000 USD. Miera návratnosti tejto investície za dva -ročné obdobie sa rovná 0, pretože počiatočná a konečná výška prostriedkov sa navzájom rovnajú. Aritmetický priemer ročnej miery návratnosti je však = (–0,5 + 1) / 2 = 0,25 alebo 25 %, pretože miera návratnosti v prvom roku R 1 = (50 000 – 100 000) / 100 000 = –0,5 , a v druhom R 2 = (100 000 – 50 000) / 50 000 = 1. Zároveň sa geometrická stredná hodnota miery zisku za dva roky rovná: G = [(1–0,5) * (1+ 1 )] 1/2 – 1 = ½ – 1 = 1 – 1 = 0. Geometrický priemer teda presnejšie odráža zmenu (presnejšie absenciu zmien) objemu investície za dvojročné obdobie ako aritmetický priemer.
Zaujímavosti. Po prvé, geometrický priemer bude vždy menší ako aritmetický priemer tých istých čísel. S výnimkou prípadu, keď sa všetky načítané čísla navzájom rovnajú. Po druhé, zvážením vlastností pravouhlého trojuholníka môžete pochopiť, prečo sa priemer nazýva geometrický. Výška pravouhlého trojuholníka zníženého do prepony je priemerná úmernosť medzi projekciami nôh na preponu a každá noha je priemerná úmernosť medzi preponou a jej projekciou do prepony (obr. 5). Toto poskytuje geometrický spôsob, ako zostrojiť geometrický priemer dvoch (dĺžok) segmentov: musíte zo súčtu týchto dvoch segmentov zostrojiť kruh ako priemer, potom výšku obnovenú od bodu ich spojenia po priesečník s kružnicou. poskytne požadovanú hodnotu:

Ryža. 5. Geometrický charakter geometrického priemeru (obrázok z Wikipédie)
Druhou dôležitou vlastnosťou číselných údajov je ich variácia, charakterizujúce stupeň rozptylu údajov. Dve rôzne vzorky sa môžu líšiť priemerom aj rozptylom. Ako je však znázornené na obr. 6 a 7, dve vzorky môžu mať rovnaké variácie, ale rôzne prostriedky, alebo rovnaké prostriedky a úplne odlišné variácie. Údaje, ktoré zodpovedajú polygónu B na obr. 7 sa menia oveľa menej ako údaje, na ktorých bol polygón A skonštruovaný.

Ryža. 6. Dve symetrické distribúcie v tvare zvona s rovnakým rozptylom a rôznymi strednými hodnotami

Ryža. 7. Dve symetrické distribúcie v tvare zvona s rovnakými strednými hodnotami a rôznymi rozpätiami
Existuje päť odhadov variácií údajov:
- rozsah,
- medzikvartilový rozsah,
- rozptyl,
- štandardná odchýlka,
- variačný koeficient.
Rozsah
Rozsah je rozdiel medzi najväčším a najmenším prvkom vzorky:
Rozsah = XMax – XMin
Rozsah vzorky obsahujúcej priemerné ročné výnosy 15 veľmi rizikových podielových fondov možno vypočítať pomocou usporiadaného poľa (pozri obrázok 4): Rozsah = 18,5 – (–6,1) = 24,6. To znamená, že rozdiel medzi najvyšším a najnižším priemerným ročným výnosom veľmi rizikových fondov je 24,6 %.
Rozsah meria celkové rozšírenie údajov. Hoci rozsah vzoriek je veľmi jednoduchým odhadom celkového rozptylu údajov, jeho slabinou je, že nezohľadňuje presne to, ako sú údaje rozdelené medzi minimálny a maximálny prvok. Tento efekt je jasne viditeľný na obr. 8, ktorý znázorňuje vzorky s rovnakým rozsahom. Stupnica B ukazuje, že ak vzorka obsahuje aspoň jednu extrémnu hodnotu, rozsah vzorky je veľmi nepresným odhadom rozptylu údajov.

Ryža. 8. Porovnanie troch vzoriek s rovnakým rozsahom; trojuholník symbolizuje oporu stupnice a jeho umiestnenie zodpovedá priemeru vzorky
Interkvartilný rozsah
Medzikvartilový alebo priemerný rozsah je rozdiel medzi tretím a prvým kvartilom vzorky:
Interkvartilové rozpätie = Q 3 – Q 1
Táto hodnota nám umožňuje odhadnúť rozptyl 50% prvkov a nebrať do úvahy vplyv extrémnych prvkov. Interkvartilné rozpätie vzorky obsahujúcej priemerné ročné výnosy 15 veľmi rizikových podielových fondov možno vypočítať pomocou údajov na obr. 4 (napríklad pre funkciu QUARTILE.EXC): Interkvartilový rozsah = 9,8 – (–0,7) = 10,5. Interval ohraničený číslami 9,8 a -0,7 sa často nazýva stredná polovica.
Je potrebné poznamenať, že hodnoty Q1 a Q3, a teda medzikvartilový rozsah, nezávisia od prítomnosti odľahlých hodnôt, pretože ich výpočet nezohľadňuje žiadnu hodnotu, ktorá by bola menšia ako Q1 alebo väčšia. ako Q3. Súhrnné miery, ako je medián, prvý a tretí kvartil a medzikvartilové rozpätie, ktoré nie sú ovplyvnené odľahlými hodnotami, sa nazývajú robustné miery.
Hoci rozsah a medzikvartilový rozsah poskytujú odhady celkového a priemerného rozptylu vzorky, ani jeden z týchto odhadov nezohľadňuje presne to, ako sú údaje rozdelené. Rozptyl a štandardná odchýlka nemajú túto nevýhodu. Tieto ukazovatele vám umožňujú posúdiť mieru, do akej údaje kolíšu okolo priemernej hodnoty. Ukážkový rozptyl je aproximáciou aritmetického priemeru vypočítaného zo štvorcov rozdielov medzi každým prvkom vzorky a priemerom vzorky. Pre vzorku X 1, X 2, ... X n je rozptyl vzorky (označený symbolom S 2 daný nasledujúcim vzorcom:

Vo všeobecnosti je rozptyl vzorky súčet druhých mocnín rozdielov medzi prvkami vzorky a priemerom vzorky, delený hodnotou rovnajúcou sa veľkosti vzorky mínus jedna:

Kde - aritmetický priemer, n- veľkosť vzorky, X i - i výberový prvok X. V Exceli pred verziou 2007 sa na výpočet rozptylu vzorky používala funkcia =VARIN(), od verzie 2010 sa používa funkcia =VARIAN().
Najpraktickejší a všeobecne akceptovaný odhad šírenia údajov je vzorová smerodajná odchýlka. Tento indikátor je označený symbolom S a rovná sa odmocnina zo vzorového rozptylu:

V Exceli pred verziou 2007 sa na výpočet smerodajnej výberovej odchýlky používala funkcia =STDEV.(), od verzie 2010 sa používa funkcia =STDEV.V(). Na výpočet týchto funkcií môže byť dátové pole neusporiadané.
Ani odchýlka vzorky, ani štandardná odchýlka vzorky nemôžu byť negatívne. Jediná situácia, v ktorej môžu byť ukazovatele S 2 a S nulové, je, ak sú všetky prvky vzorky navzájom rovnaké. V tomto úplne nepravdepodobnom prípade je rozsah a medzikvartilový rozsah tiež nulový.
Číselné údaje sú vo svojej podstate nestále. Každá premenná môže nadobúdať rôzne hodnoty. Napríklad rôzne podielové fondy majú rôznu mieru návratnosti a straty. Vzhľadom na variabilitu číselných údajov je veľmi dôležité študovať nielen odhady priemeru, ktoré majú súhrnný charakter, ale aj odhady rozptylu, ktoré charakterizujú rozptyl údajov.
Rozptyl a štandardná odchýlka vám umožňujú vyhodnotiť rozptyl údajov okolo priemernej hodnoty, inými slovami, určiť, koľko prvkov vzorky je menších ako priemer a koľko väčších. Disperzia má niektoré cenné matematické vlastnosti. Jeho hodnota je však druhá mocnina mernej jednotky – štvorcové percento, štvorcový dolár, štvorcový palec atď. Preto je prirodzenou mierou rozptylu štandardná odchýlka, ktorá je vyjadrená v bežných jednotkách percenta príjmu, dolároch alebo palcoch.
Smerodajná odchýlka vám umožňuje odhadnúť množstvo variácií prvkov vzorky okolo priemernej hodnoty. Takmer vo všetkých situáciách sa väčšina pozorovaných hodnôt nachádza v rozmedzí plus alebo mínus jednej štandardnej odchýlky od priemeru. V dôsledku toho, keď poznáme aritmetický priemer prvkov vzorky a štandardnú odchýlku vzorky, je možné určiť interval, do ktorého patrí väčšina údajov.
Štandardná odchýlka výnosov pre 15 veľmi rizikových podielových fondov je 6,6 (obrázok 9). To znamená, že výnosnosť väčšiny fondov sa od priemernej hodnoty líši najviac o 6,6 % (t. j. kolíše v rozmedzí od – S= 6,2 – 6,6 = –0,4 až +S= 12,8). V skutočnosti je päťročný priemerný ročný výnos 53,3 % (8 z 15) fondov v tomto rozmedzí.

Ryža. 9. Štandardná odchýlka vzorky
Všimnite si, že pri sčítaní štvorcových rozdielov sa položky vzorky, ktoré sú ďalej od priemeru, vážia viac ako položky, ktoré sú bližšie k priemeru. Táto vlastnosť je hlavným dôvodom, prečo sa aritmetický priemer najčastejšie používa na odhad priemeru rozdelenia.
Variačný koeficient
Na rozdiel od predchádzajúcich odhadov rozptylu je variačný koeficient relatívnym odhadom. Vždy sa meria v percentách a nie v jednotkách pôvodných údajov. Variačný koeficient, označený symbolmi CV, meria rozptyl údajov okolo priemeru. Variačný koeficient sa rovná štandardnej odchýlke vydelenej aritmetickým priemerom a vynásobenej 100 %:

Kde S- štandardná odchýlka vzorky, - vzorový priemer.
Variačný koeficient vám umožňuje porovnať dve vzorky, ktorých prvky sú vyjadrené v rôznych jednotkách merania. Napríklad manažér poštovej doručovacej služby má v úmysle obnoviť svoj vozový park. Pri nakladaní balíkov je potrebné zvážiť dve obmedzenia: hmotnosť (v librách) a objem (v kubických stopách) každého balíka. Predpokladajme, že vo vzorke obsahujúcej 200 vriec je priemerná hmotnosť 26,0 libier, štandardná odchýlka hmotnosti je 3,9 libier, stredný objem vrecka je 8,8 kubických stôp a štandardná odchýlka objemu je 2,2 kubických stôp. Ako porovnať rozdiely v hmotnosti a objeme balíkov?
Keďže merné jednotky hmotnosti a objemu sa navzájom líšia, manažér musí porovnávať relatívne rozloženie týchto veličín. Koeficient variácie hmotnosti je CV W = 3,9 / 26,0 * 100 % = 15 % a koeficient variácie objemu je CV V = 2,2 / 8,8 * 100 % = 25 %. Relatívna odchýlka v objeme paketov je teda oveľa väčšia ako relatívna odchýlka v ich hmotnosti.
Distribučný formulár
Treťou dôležitou vlastnosťou vzorky je tvar jej rozloženia. Toto rozdelenie môže byť symetrické alebo asymetrické. Na opísanie tvaru rozdelenia je potrebné vypočítať jeho priemer a medián. Ak sú tieto dve rovnaké, premenná sa považuje za symetricky rozloženú. Ak je stredná hodnota premennej väčšia ako medián, jej rozdelenie má kladnú šikmosť (obr. 10). Ak je medián väčší ako priemer, distribúcia premennej je negatívne skreslená. Pozitívna šikmosť nastáva, keď sa priemer zvýši na nezvyčajne vysoké hodnoty. Negatívna šikmosť nastane, keď priemer klesne na nezvyčajne malé hodnoty. Premenná je symetricky rozdelená, ak nenadobúda žiadne extrémne hodnoty v žiadnom smere, takže veľké a malé hodnoty premennej sa navzájom rušia.

Ryža. 10. Tri typy rozvodov
Údaje uvedené na stupnici A sú negatívne skreslené. Tento obrázok ukazuje dlhý chvost a ľavé zošikmenie spôsobené prítomnosťou nezvyčajne malých hodnôt. Tieto extrémne malé hodnoty posúvajú priemernú hodnotu doľava, čím je menšia ako medián. Údaje zobrazené na stupnici B sú rozdelené symetricky. Ľavá a pravá polovica distribúcie sú zrkadlovým obrazom samých seba. Veľké a malé hodnoty sa navzájom vyrovnávajú a priemer a medián sú rovnaké. Údaje zobrazené na stupnici B sú pozitívne skreslené. Tento obrázok ukazuje dlhý chvost a zošikmenie doprava spôsobené prítomnosťou nezvyčajne vysokých hodnôt. Tieto príliš veľké hodnoty posúvajú priemer doprava, čím je väčší ako medián.
V Exceli je možné získať popisnú štatistiku pomocou doplnku Analytický balík. Prejdite si menu Údaje → Analýza dát, v okne, ktoré sa otvorí, vyberte riadok Deskriptívna štatistika a kliknite Dobre. V okne Deskriptívna štatistika určite uveďte Interval vstupu(obr. 11). Ak chcete zobraziť popisnú štatistiku na rovnakom hárku ako pôvodné údaje, vyberte prepínač Výstupný interval a zadajte bunku, do ktorej má byť umiestnený ľavý horný roh zobrazenej štatistiky (v našom príklade $C$1). Ak chcete odosielať údaje do nový list alebo v nová kniha, stačí vybrať príslušný prepínač. Začiarknite políčko vedľa Súhrnná štatistika. Ak chcete, môžete si tiež vybrať Obtiažnosť,k-tý najmenší ak-tá najväčšia.
Ak na zálohu Údaje v oblasti Analýza nevidíte ikonu Analýza dát, musíte najprv nainštalovať doplnok Analytický balík(pozri napríklad).

Ryža. 11. Popisná štatistika päťročných priemerných ročných výnosov fondov s veľmi vysokou mierou rizika vypočítaná pomocou doplnku Analýza dát Excel programy
Excel vypočítava množstvo štatistík uvedených vyššie: priemer, medián, režim, štandardná odchýlka, rozptyl, rozsah ( interval), minimálna, maximálna a veľkosť vzorky ( skontrolovať). Excel tiež vypočítava niektoré štatistiky, ktoré sú pre nás nové: štandardná chyba, špičatosť a šikmosť. Štandardná chyba rovná štandardnej odchýlke vydelenej druhou odmocninou veľkosti vzorky. Asymetria charakterizuje odchýlku od symetrie rozdelenia a je funkciou, ktorá závisí od kocky rozdielov medzi prvkami vzorky a priemernou hodnotou. Kurtóza je miera relatívnej koncentrácie údajov okolo priemeru v porovnaní s koncami distribúcie a závisí od rozdielov medzi prvkami vzorky a priemerom zvýšeným na štvrtú mocninu.
Výpočet popisnej štatistiky pre populáciu
Priemer, rozptyl a tvar distribúcie diskutovaný vyššie sú charakteristiky určené zo vzorky. Ak však súbor údajov obsahuje číselné merania celej populácie, jeho parametre sa dajú vypočítať. Medzi takéto parametre patrí očakávaná hodnota, rozptyl a štandardná odchýlka populácie.
Očakávaná hodnota rovná sa súčtu všetkých hodnôt v populácii vydelenému veľkosťou populácie:

Kde µ - očakávaná hodnota, Xi- i pozorovanie premennej X, N- objem bežnej populácie. V Exceli sa na výpočet matematického očakávania používa rovnaká funkcia ako pre aritmetický priemer: =AVERAGE().
Populačný rozptyl rovný súčtu štvorcov rozdielov medzi prvkami bežnej populácie a mat. očakávanie delené veľkosťou populácie:

Kde σ 2– rozptyl bežnej populácie. V Exceli pred verziou 2007 sa funkcia =VARP() používa na výpočet rozptylu populácie, počnúc verziou 2010 =VARP().
Smerodajná odchýlka populácie rovná sa druhej odmocnine populačného rozptylu:

V Exceli pred verziou 2007 sa funkcia =STDEV() používa na výpočet štandardnej odchýlky populácie, počnúc verziou 2010 =STDEV.Y(). Všimnite si, že vzorce pre rozptyl populácie a štandardnú odchýlku sa líšia od vzorcov na výpočet rozptylu vzorky a štandardnej odchýlky. Pri výpočte štatistických údajov vzorky S 2 A S menovateľ zlomku je n – 1 a pri výpočte parametrov σ 2 A σ - objem bežnej populácie N.
Pravidlo palca
Vo väčšine situácií sa veľká časť pozorovaní sústreďuje okolo mediánu a vytvára zhluk. V súboroch údajov s kladným zošikmením je tento zhluk umiestnený naľavo (t. j. pod) od matematického očakávania a v súboroch s negatívnym zošikmením je tento zhluk umiestnený napravo (t. j. nad) od matematického očakávania. Pre symetrické údaje sú priemer a medián rovnaké a pozorovania sa zhlukujú okolo priemeru, čím sa vytvorí zvonovitá distribúcia. Ak distribúcia nie je jasne skreslená a údaje sú sústredené okolo ťažiska, na odhad variability sa dá použiť pravidlo, že ak majú údaje zvonovité rozdelenie, potom približne 68 % pozorovaní je v rámci jedna smerodajná odchýlka očakávanej hodnoty.približne 95 % pozorovaní nie je viac ako dve smerodajné odchýlky od matematického očakávania a 99,7 % pozorovaní nie je viac ako tri smerodajné odchýlky od matematického očakávania.
Preto štandardná odchýlka, ktorá je odhadom priemernej variácie okolo očakávanej hodnoty, pomáha pochopiť, ako sú pozorovania rozdelené, a identifikovať odľahlé hodnoty. Pravidlom je, že pre zvonovité rozdelenia sa iba jedna hodnota z dvadsiatich líši od matematického očakávania o viac ako dve štandardné odchýlky. Preto hodnoty mimo intervalu u ± 2σ, možno považovať za odľahlé hodnoty. Okrem toho len tri z 1000 pozorovaní sa líšia od matematického očakávania o viac ako tri štandardné odchýlky. Teda hodnoty mimo intervalu u ± 3σ sú takmer vždy odľahlé. Pre distribúcie, ktoré sú veľmi šikmé alebo nemajú zvonovitý tvar, možno použiť Bienamay-Chebyshevovo pravidlo.
Pred viac ako sto rokmi matematici Bienamay a Chebyshev nezávisle objavili užitočný majetok smerodajná odchýlka. Zistili, že pre akýkoľvek súbor údajov, bez ohľadu na tvar distribúcie, percento pozorovaní, ktoré ležia vo vzdialenosti kštandardné odchýlky od matematického očakávania, nie menej (1 – 1/ k 2)*100 %.
Napríklad, ak k= 2, pravidlo Bienname-Chebyshev hovorí, že aspoň (1 – (1/2) 2) x 100 % = 75 % pozorovaní musí ležať v intervale u ± 2σ. Toto pravidlo platí pre každého k, presahujúce jednu. Bienamay-Čebyševovo pravidlo je veľmi všeobecné a platné pre distribúcie akéhokoľvek typu. Špecifikuje minimálny počet pozorovaní, pričom vzdialenosť, od ktorej k matematickému očakávaniu nepresahuje stanovenú hodnotu. Ak je však rozdelenie v tvare zvona, pravidlo presnejšie odhadne koncentráciu údajov okolo očakávanej hodnoty.
Výpočet popisných štatistík pre frekvenčne založené rozdelenie
Ak pôvodné údaje nie sú k dispozícii, jediným zdrojom informácií sa stáva rozdelenie frekvencií. V takýchto situáciách je možné vypočítať približné hodnoty kvantitatívnych ukazovateľov rozdelenia, ako je aritmetický priemer, štandardná odchýlka a kvartily.
Ak sú údaje vzorky reprezentované ako frekvenčné rozdelenie, aproximáciu aritmetického priemeru možno vypočítať za predpokladu, že všetky hodnoty v rámci každej triedy sú sústredené v strede triedy:

Kde - priemer vzorky, n- počet pozorovaní alebo veľkosť vzorky, s- počet tried vo frekvenčnom rozdelení, m j- stredný bod j trieda, fj- frekvencia zodpovedajúca j- trieda.
Na výpočet štandardnej odchýlky od rozdelenia frekvencií sa tiež predpokladá, že všetky hodnoty v rámci každej triedy sú sústredené v strede triedy.

Aby sme pochopili, ako sa kvartily série určujú na základe frekvencií, zvážte výpočet dolného kvartilu na základe údajov za rok 2013 o rozdelení ruskej populácie podľa priemerného peňažného príjmu na obyvateľa (obr. 12).

Ryža. 12. Podiel ruského obyvateľstva s priemerným peňažným príjmom na obyvateľa za mesiac, v rubľoch
Na výpočet prvého kvartilu série variácií intervalu môžete použiť vzorec:

kde Q1 je hodnota prvého kvartilu, xQ1 je spodná hranica intervalu obsahujúceho prvý kvartil (interval je určený akumulovanou frekvenciou, ktorá ako prvá prekročí 25 %); i – intervalová hodnota; Σf – súčet frekvencií celej vzorky; pravdepodobne sa vždy rovná 100 %; SQ1–1 – akumulovaná frekvencia intervalu predchádzajúceho intervalu obsahujúcemu dolný kvartil; fQ1 – frekvencia intervalu obsahujúceho dolný kvartil. Vzorec pre tretí kvartil sa líši v tom, že na všetkých miestach musíte použiť Q3 namiesto Q1 a nahradiť ¾ namiesto ¼.
V našom príklade (obr. 12) je dolný kvartil v rozmedzí 7000,1 – 10 000, ktorého akumulovaná frekvencia je 26,4 %. Dolná hranica tohto intervalu je 7 000 rubľov, hodnota intervalu je 3 000 rubľov, akumulovaná frekvencia intervalu predchádzajúceho intervalu obsahujúceho dolný kvartil je 13,4 %, frekvencia intervalu obsahujúceho dolný kvartil je 13,0 %. Teda: Q1 = 7000 + 3000 * (¼ * 100 – 13,4) / 13 = 9677 rub.
Úskalia spojené s popisnou štatistikou
V tomto príspevku sme sa pozreli na to, ako opísať množinu údajov pomocou rôznych štatistík, ktoré vyhodnocujú jej priemer, rozšírenie a distribúciu. Ďalším krokom je analýza a interpretácia údajov. Doteraz sme skúmali objektívne vlastnosti údajov a teraz prejdeme k ich subjektívnej interpretácii. Výskumník čelí dvom chybám: nesprávne zvolenému predmetu analýzy a nesprávnej interpretácii výsledkov.
Analýza výnosov 15 veľmi rizikových podielových fondov je celkom nezaujatá. Dospel k úplne objektívnym záverom: všetky podielové fondy majú rozdielne výnosy, spread výnosov fondov sa pohybuje od -6,1 do 18,5 a priemerný výnos je 6,08. Objektivita analýzy dát je zabezpečená správna voľba celkové kvantitatívne ukazovatele distribúcie. Zvažovalo sa niekoľko metód odhadu priemeru a rozptylu údajov a naznačili sa ich výhody a nevýhody. Ako si vybrať správnu štatistiku, ktorá poskytne objektívnu a nestrannú analýzu? Ak je distribúcia údajov mierne skreslená, mali by ste zvoliť skôr medián ako priemer? Ktorý ukazovateľ presnejšie charakterizuje šírenie údajov: smerodajná odchýlka alebo rozsah? Mali by sme poukázať na to, že distribúcia je pozitívne skreslená?
Na druhej strane je interpretácia údajov subjektívnym procesom. Rôzni ľudia prichádzajú k rôznym záverom pri interpretácii rovnakých výsledkov. Každý má svoj vlastný uhol pohľadu. Niekto považuje celkové priemerné ročné výnosy 15 fondov s veľmi vysokou mierou rizika za dobré a je celkom spokojný s dosiahnutým príjmom. Iní môžu mať pocit, že tieto fondy majú príliš nízke výnosy. Subjektivita by teda mala byť kompenzovaná čestnosťou, neutralitou a jasnosťou záverov.
Etické problémy
Analýza údajov je neoddeliteľne spojená s etickými otázkami. Mali by ste byť kritickí k informáciám šíreným novinami, rádiom, televíziou a internetom. Časom sa naučíte byť skeptickí nielen k výsledkom, ale aj k cieľom, predmetu a objektivite výskumu. Slávny britský politik Benjamin Disraeli to povedal najlepšie: „Existujú tri druhy klamstiev: klamstvá, prekliate klamstvá a štatistiky.
Ako sa uvádza v poznámke, pri výbere výsledkov, ktoré by sa mali prezentovať v správe, vznikajú etické problémy. Mali by sa zverejňovať pozitívne aj negatívne výsledky. Okrem toho pri vypracovaní správy alebo písomnej správy musia byť výsledky prezentované čestne, neutrálne a objektívne. Je potrebné rozlišovať medzi neúspešnými a nečestnými prezentáciami. Na to je potrebné určiť, aké boli úmysly rečníka. Niekedy rečník vynechá dôležité informácie z neznalosti a niekedy je to zámerne (napríklad ak použije aritmetický priemer na odhadnutie priemeru jasne skreslených údajov na získanie požadovaného výsledku). Nečestné je aj potláčanie výsledkov, ktoré nezodpovedajú pohľadu výskumníka.
Používajú sa materiály z knihy Levin et al Štatistika pre manažérov. – M.: Williams, 2004. – s. 178–209
Funkcia QUARTILE bola zachovaná kvôli kompatibilite so staršími verziami Excelu.
Aritmetický priemer je štatistický ukazovateľ, ktorý ukazuje priemernú hodnotu daného dátového poľa. Tento ukazovateľ sa vypočíta ako zlomok, ktorého čitateľ je súčtom všetkých hodnôt v poli a menovateľom je ich počet. Aritmetický priemer je dôležitý koeficient, ktorý sa používa pri každodenných výpočtoch.
Význam koeficientu
Aritmetický priemer je základným ukazovateľom na porovnanie údajov a výpočet prijateľnej hodnoty. V rôznych obchodoch sa napríklad predáva plechovka piva od konkrétneho výrobcu. Ale v jednom obchode to stojí 67 rubľov, v inom - 70 rubľov, v treťom - 65 rubľov a v poslednom - 62 rubľov. Existuje pomerne široký rozsah cien, takže kupujúceho budú zaujímať priemerné náklady na plechovku, aby si pri nákupe produktu mohol porovnať svoje náklady. Priemerná cena za plechovku piva v meste je:
Priemerná cena = (67 + 70 + 65 + 62) / 4 = 66 rubľov.
Keď poznáte priemernú cenu, je ľahké určiť, kde je výhodné kúpiť produkt a kde budete musieť preplatiť.
Aritmetický priemer sa neustále používa v štatistických výpočtoch v prípadoch, keď sa analyzuje homogénny súbor údajov. Vo vyššie uvedenom príklade ide o cenu plechovky piva rovnakej značky. Nemôžeme však porovnávať cenu piva od rôznych výrobcov alebo ceny piva a limonády, pretože v tomto prípade bude rozptyl hodnôt väčší, priemerná cena bude rozmazaná a nespoľahlivá a samotný význam výpočtov bude skreslená do karikatúry „priemernej teploty v nemocnici“. Na výpočet heterogénnych súborov údajov sa používa vážený aritmetický priemer, keď každá hodnota dostane svoj vlastný váhový koeficient.
Výpočet aritmetického priemeru
Vzorec na výpočty je veľmi jednoduchý:
P = (a1 + a2 + … an) / n,
kde a je hodnota veličiny, n je celkový počet hodnôt.
Na čo sa dá tento ukazovateľ použiť? Prvé a zrejmé využitie je v štatistike. Takmer každá štatistická štúdia používa aritmetický priemer. To môže byť priemerný vek manželstvo v Rusku, priemerná známka z predmetu pre školáka alebo priemerné výdavky na potraviny za deň. Ako je uvedené vyššie, bez zohľadnenia váh môže výpočet priemerov produkovať zvláštne alebo absurdné hodnoty.
Napríklad prezident Ruská federácia urobil vyhlásenie, že podľa štatistík je priemerný plat Rusa 27 000 rubľov. Pre väčšinu obyvateľov Ruska sa táto úroveň platu zdala absurdná. Nie je prekvapujúce, ak pri výpočte berieme do úvahy príjmy oligarchov, šéfov priemyselných podnikov, veľkých bankárov na jednej strane a platy učiteľov, upratovačiek a predavačov na strane druhej. Dokonca aj priemerné platy v jednej špecializácii, napríklad účtovník, budú mať vážne rozdiely v Moskve, Kostrome a Jekaterinburgu.
Ako vypočítať priemery pre heterogénne údaje
V mzdových situáciách je dôležité zvážiť váhu každej hodnoty. To znamená, že platy oligarchov a bankárov by dostali váhu napríklad 0,00001 a platy predajcov - 0,12. Sú to čísla z ničoho nič, ale zhruba ilustrujú prevahu oligarchov a predajcov v ruskej spoločnosti.
Na výpočet priemeru priemerov alebo priemerných hodnôt v súbore heterogénnych údajov je teda potrebné použiť aritmetický vážený priemer. V opačnom prípade dostanete priemerný plat v Rusku 27 000 rubľov. Ak chcete zistiť svoju priemernú známku z matematiky alebo priemerný počet strelených gólov vybraného hokejistu, potom je pre vás vhodná kalkulačka aritmetického priemeru.
Náš program je jednoduchá a pohodlná kalkulačka na výpočet aritmetického priemeru. Na vykonanie výpočtov stačí zadať hodnoty parametrov.
Pozrime sa na pár príkladov
Výpočet priemerného skóre
Mnoho učiteľov používa metódu aritmetického priemeru na určenie ročnej známky za predmet. Predstavme si, že dieťa dostalo z matematiky tieto štvrťročné známky: 3, 3, 5, 4. Akú ročnú známku mu dá učiteľ? Použime kalkulačku a vypočítajme aritmetický priemer. Ak chcete začať, vyberte príslušný počet polí a do zobrazených buniek zadajte hodnoty hodnotenia:
(3 + 3 + 5 + 4) / 4 = 3,75
Učiteľ zaokrúhli hodnotu v prospech žiaka a žiak dostane solídne B za ročník.
Výpočet zjedených cukríkov
Ukážme si niektoré absurdity aritmetického priemeru. Predstavme si, že Máša a Vova mali 10 cukríkov. Máša zjedla 8 cukríkov a Vova len 2. Koľko cukríkov priemerne zjedlo každé dieťa? Pomocou kalkulačky sa dá ľahko vypočítať, že priemerne deti zjedli 5 cukríkov, čo je úplne v rozpore s realitou a zdravým rozumom. Tento príklad ukazuje, že aritmetický priemer je dôležitý pre zmysluplné súbory údajov.
Záver
Výpočet aritmetického priemeru je široko používaný v mnohých vedeckých oblastiach. Tento ukazovateľ je obľúbený nielen v štatistických výpočtoch, ale aj vo fyzike, mechanike, ekonómii, medicíne alebo financiách. Použite naše kalkulačky ako pomocníka pri riešení problémov s výpočtom aritmetického priemeru.